
You must have heard about podcasts. They’re like really cool radio shows that people can listen to on their phones or computers. Lots of people love listening to them because they tell interesting stories, share facts, and make people laugh or learn new things.
In this article, we will see how to use Gen AI to create our own podcast content in a really amazing way. It’s like adding magical powers to the stories and shows we make!
Gen AI (Generative AI):
“Gen AI” is a broader term that refers to a class of AI systems designed to generate content autonomously. This content can include text, images, music, videos, and more. These systems leverage generative algorithms and models to create content that often simulates human creativity and style. Gen AI encompasses a wide range of AI models, including language models like LLMs, as well as models specifically designed for generating other types of content like images or music.
LLM (Large Language Model):
LLMs are a specific subset of Generative AI models that are focused on generating human-like text. These models are trained on massive amounts of text data to understand the patterns, structure, and context of language. LLMs like GPT-3 (Generative Pre-trained Transformer 3) are capable of generating coherent and contextually relevant text based on the input they receive. They can perform tasks such as answering questions, generating stories, providing explanations, and more by predicting the next words or phrases in a given text sequence.
In summary, “Gen AI” is a broader category that includes various AI systems for generating different types of content, while “LLM” specifically refers to large language models that generate text-based content.
Now, let’s explore how we can create the content for an interactive and engaging podcast using AI. You can choose any interesting topic from the internet for your podcast. The upcoming steps will demonstrate how to utilize various AI tools to generate the podcast’s content:
- Setting Up the Notebook
- Choose a Podcast Topic
- Gather Content
- Preprocessing and Data Chunking
- Data Summarization
- Generate the Podcast Script
- Add Voice to the Podcast Script
- Generate Podcast Intro Music
- Bring the Podcast Together
1. Setting Up the Notebook
We’ll be using a Google Colab notebook for this, but you can use any Jupyter notebook environment.
First, let’s open a new notebook and create some headings. After that, we’ll connect to the runtime.

For this tutorial, we will be using the OpenAI GPT-3.5 model. To use this model, we will need an API key. If you’ve already signed up with OpenAI, you can generate a new key from the profile section or use any existing key.

If you have not signed in yet then you can use the below URL to sign-in to OpenAI and then get the key from the profile section.
Copy and save the API key in a secure location. We’ll need to use this key later on.
2. Choose a Podcast Topic
The initial step in creating a podcast is to choose a topic and gather content that will serve as the backbone of our podcast. In this instance, we’ll utilize Wikipedia data to generate the text corpus. However, there are other methods available for generating content for our podcast as well. In our case, we’ll be creating a podcast centered around Lionel Messi, the legendary footballer. Given my fondness for Messi, I’m inclined toward this topic, but you’re free to select any other topic of your preference.
3. Gather Content
Wikipedia is a great source for gathering information about the history, current events, celebrities and so much more! It’s a good starting point for our text corpus. Using the Wikipedia library, we can get all the details of a certain Wiki page based on the title or the Wiki ID.
To proceed with our tutorial, we’ll need to install several libraries in the Colab notebook. Let’s begin by installing the Wikipedia library using the command below.
!pip install wikipediaOnce the library is installed let’s verify if we can extract the content of any page from Wikipedia.
import wikipedia
print (wikipedia.summary("Wikipedia"))As we can see below the library is successfully installed and we are able to extract content from Wikipedia.
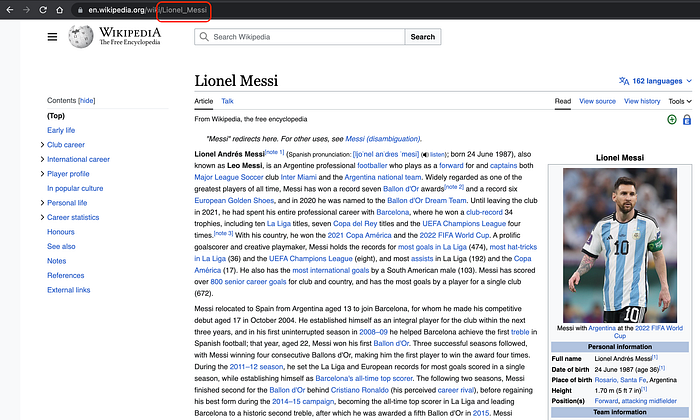
Moving forward, let’s collect some information about Lionel Messi from Wikipedia. As previously mentioned, feel free to choose a different topic if you prefer. When we access Lionel Messi’s Wikipedia page, you’ll notice that the Wiki ID appears at the end of the URI. We’ll utilize this ID to fetch the necessary data.
input = wikipedia.page("Lionel_Messi", auto_suggest=False)
wiki_input = input.content
print (len(wiki_input))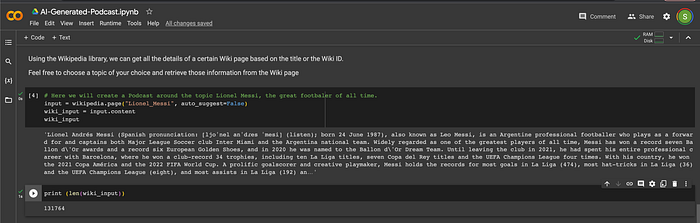
As shown above, the text corpus is substantial, encompassing 131,764 characters. However, we can’t utilize this data as is. The limitation arises from the context length of Large Language Models (LLMs), which determines the extent of text they can comprehend at once. Each LLM model has its own context length, and they process text within this constraint. So, how can we address this challenge? Let’s explore the solution in the next step.
4. Preprocessing and Data Chunking
Before training any machine learning model, it’s important to perform data cleaning. Likewise, before providing data as input to an LLM, we should perform both data cleaning and chunking.
Data chunking is a strategy to work around the Large Language Models (LLMs) context window limitation and ensure that longer texts can be effectively processed by the model. It involves dividing the text into sections that are within the model’s context window size, processing these sections sequentially, and handling any inter-chunk dependencies to maintain the flow of the narrative.
What are tokens in the context of LLM?
In the context of Large Language Models (LLMs) like GPT-3, tokens refer to the individual units that text is broken down into. A token can be as short as a single character or as long as a word. For example:
- The word “apple” is one token.
- The phrase “New York” is two tokens, as it consists of two words.
- The sentence “I love ice cream” is four tokens: [“I”, “love”, “ice”, “cream”].
Large Language Models have limitations on the maximum number of tokens they can process in a single input due to computational constraints. This limitation requires users to be mindful of input length, especially when dealing with lengthy texts.
Here, we will use tiktoken library from OpenAI to overcome the token limitation.
We will use the below command to install this library.
!pip install tiktokenLet’s check the total number of tokens present in our text corpus.
import tiktoken
enc = tiktoken.encoding_for_model("gpt-3.5-turbo")
print ("Number of tokens in corpus ", len(enc.encode(wiki_input)))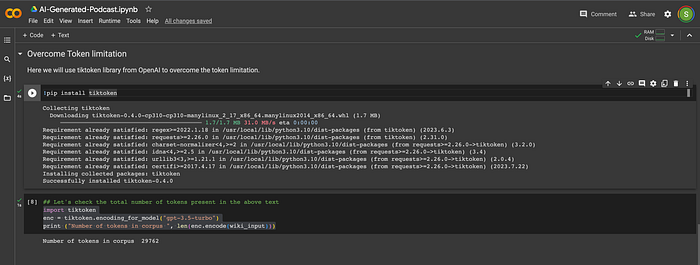
As we can see above, the number of tokens is large for our text corpus. So, we will need to do some processing to divide the corpus into batches before sending it to OpenAI. In this tutorial, we’ll be using the GPT-3.5-turbo model, which has a maximum token length of 4k. This limit is much lower than the token length of our text corpus.
Merely splitting the text corpus based on token length isn’t sufficient, as doing so might lead to the loss of sentence meanings when we send the chunk to ChatGPT. Therefore, our approach involves initially segmenting the text corpus into coherent sections and subsequently evaluating the token length by combining these subsections.
To split our text corpus we will use the library called NLTK. The sent_tokenize function from the NLTK library can help us to tokenize the text into logical sentences.
We’ll create some helper functions to divide our text corpus into smaller chunks making it suitable for processing by the GPT-3.5 model within a single request. These chunks will be grouped into batches, with each chunk limited to a maximum of 2,500 tokens.
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
# Return a sentence-tokenized copy of text, using NLTK’s recommended sentence tokenizer (currently PunktSentenceTokenizer for the specified language).
def split_text (input_text):
split_texts = sent_tokenize(input_text)
return split_texts
def create_chunks(split_sents, max_token_len=2500):
current_token_len = 0
input_chunks = []
current_chunk = ""
for sents in split_sents:
sent_token_len = len(enc.encode(sents))
if (current_token_len + sent_token_len) > max_token_len:
input_chunks.append(current_chunk)
current_chunk = ""
current_token_len = 0
current_chunk = current_chunk + sents
current_token_len = current_token_len + sent_token_len
if current_chunk != "":
input_chunks.append(current_chunk)
return input_chunksLet’s now use the above function to split our text corpus.
split_sents = split_text(wiki_input)
input_chunks = create_chunks(split_sents, max_token_len=2500)
print(f'Batch size: {len(input_chunks)}')
# Batch size: 13Now, our total batch size is 13, with approximately 2500 tokens in each batch.
5. Data Summarization
We’ll now construct a prompt for the LLM, using the input text corpus, to generate a summary. This helps us pinpoint the crucial themes and standout points of the selected topic. This summary will serve as a foundation for creating our podcast script. Remember, a simple summary might be too brief and not provide adequate context for an in-depth podcast discussion. Hence, we need to ensure that the summary contains the most important highlights of the topic that we want to be a part of the podcast conversation.
Moving forward, let’s install the Openai package and ensure that it works seamlessly with our API key.
!pip install openaiimport openai
from getpass import getpass
openai.api_key = getpass('Enter your OPENAI_API_KEY')# we can confirm that the API key works by listing all the OpenAI models
# we will be using the gpt-3.5-turbo version for this project
models = openai.Model.list()
for model in models["data"]:
print (model["root"])
Let’s proceed to instruct ChatGPT to craft a summary from our text corpus. We’ve reached the stage where we’ve segmented our source text into chunks, and now it’s time to collaborate with ChatGPT to generate the podcast’s summary.
Remember, we’re not seeking a typical summary here — our goal is to create a summary that holds enough content for a captivating podcast discussion. Additionally, it’s important that the information is presented in a structured manner, facilitating easy parsing and reuse for the next step.
Let’s generate a sample prompt for the topic we’ve chosen. We’ll attempt to create a general prompt that can be adapted for various topics. Don’t hesitate to experiment with different prompts. The prompt provided below is meant to offer some guidance in summarizing the text corpus for our podcast creation.
topic = "Sports"
instructPrompt = f"""
You are a {topic} enthusiast who is doing a research for a podcast. Your task is to extract relevant information from the Result delimited by triple quotes.
Please identify 2 interesting questions and answers which can be used for a podcast discussion.
The identified discussions should be returned in the following format.
- Highlight 1 from the text
- Highlight 2 from the text
"""
requestMessages = []
for text in input_chunks:
requestMessage = instructPrompt + f"Result: ```{text}```"
requestMessages.append(requestMessage)Next, we’ll proceed to execute these prompts to summarize our text corpus and gather the results.
chatOutputs = []
for request in requestMessages:
chatOutput = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": request}
]
)
chatOutputs.append(chatOutput)podcastFacts = ""
for chats in chatOutputs:
podcastFacts = podcastFacts + chats.choices[0].message.contentWe got the below summary.
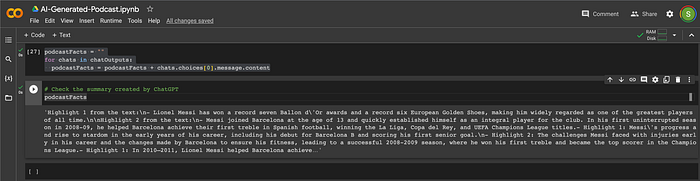
The output above should present a list of significant facts, themes, or highlights from our chosen topic. These are the aspects we’d like to address in the podcast conversation.
6. Generate the Podcast Script
We now possess all the essential facts and highlights that we intend to incorporate into our podcast episode. With this foundation, let’s proceed to create a podcast script using these highlighted points.
For this purpose, let’s formulate a new prompt that will guide ChatGPT in generating the podcast script using the aforementioned highlights.
While large-language models exhibit impressive capabilities even with zero-shot prompting, they can encounter challenges with more complex tasks. In such cases, we need to provide thinking time to LLM models. It might be helpful to provide clear instructions with defined steps. It’s a similar way to how we offer stepwise instructions to a child.
Below, you’ll find the prompt utilized to generate the podcast script. In this prompt, we’ve designated ‘Tom’ as the main host of the podcast and ‘Jerry’ as the co-host.
podcast_name = "Sport 101"
podcastPrompt = f"""
You are a writer creating the script for the another episode of a podcast {podcast_name} hosted by \"Tom\" and \"Jerry\".
Use \"Tom\" as the person asking questions and \"Jerry\" as the person providing interesting insights to those questions.
Always specify speaker name as \"Tom\" or \"Jerry\" to identify who is speaking.
Make the convesation casual and interesting.
Extract relevant information for the podcast conversation from the Result delimited by triple quotes.
Use the below format for the podcast conversation.
1. Introduction about the topic and welcome everyone for another episode of the podcast {podcast_name}.
2. Tom is the main host.
2. Introduce both the speakers in brief.
3. Then start the conversation.
4. Start the conversation with some casual discussion like what they are doing right now at this moment.
5. End the conversation with thank you speech to everyone.
6. Do not use the word \"conversation\" response.
"""
requestMessage = podcastPrompt + f"Result: ```{podcastFacts}```"Let’s now use this prompt to generate the podcast script using the below command.
finalOutput = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": requestMessage}
],
temperature = 0.7
)Below is the sample podcast script that we received as a response from ChatGPT.
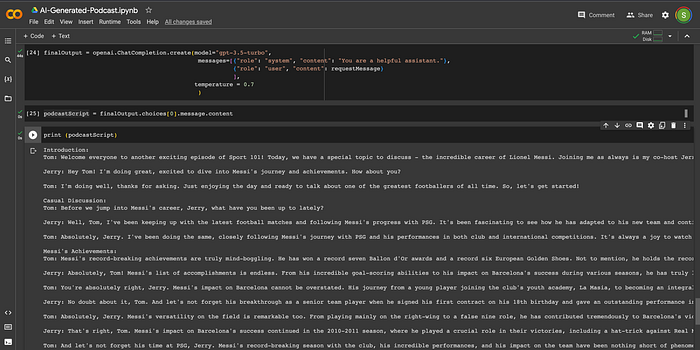
7. Add Voice to the Podcast Script
Our podcast script is now prepared, and all that’s left is to have human voices read this script. To accomplish this, we will employ ElevenLabs for voice generation.
ElevenLabs leverages advanced AI technology to produce top-notch spoken audio in various voices, styles, and languages.
Initially, we’ll need to sign up for ElevenLabs and generate the API key. Upon registration, we’re granted complimentary credits, which are more than sufficient for generating the audio required for our podcast.
To sign up, we can use the URL provided below.
Once we have completed the sign-up process, we need to navigate to the profile settings to access the API Key. Make sure to keep this API key secure, as it will be required for future steps.

We can use the below command to install the dependency first.
!pip install elevenlabsLet’s set the API Key for ElevenLabs next.
from elevenlabs import set_api_key
set_api_key(getpass('Enter your ELEVEN_LABS_API_KEY '))In ElevenLabs, we will find a variety of speakers listed in their demo dropdown. They offer a playground feature where we can select different speakers to listen to their voices. Simply choose a speaker and click the play button to hear their voice. For our interactive podcast, we’ll need to select two speakers.
After finalizing our choice of speakers, make a note of their names. We’ll need this information for the next steps.
To facilitate voice generation, we’ll create a helper method. This method assumes that each line of the input text is spoken by a distinct person, and the person’s name is included within the text. It’s important to ensure that the output of our podcast script adheres to this style. If needed, feel free to modify the method accordingly.
from elevenlabs import generate
def createPodcast(podcastScript, speakerName1, speakerChoice1, speakerName2, speakerChoice2):
genPodcast = []
podcastLines = podcastScript.split('\n\n')
podcastLineNumber = 0
for line in podcastLines:
if podcastLineNumber % 2 == 0:
speakerChoice = speakerChoice1
line = line.replace(speakerName1+":", '')
else:
speakerChoice = speakerChoice2
line = line.replace(speakerName2+":", '')
genVoice = generate(text=line, voice=speakerChoice, model="eleven_monolingual_v1")
genPodcast.append(genVoice)
podcastLineNumber += 1
return genPodcastspeakerName1 = "Tom"
speakerChoice1 = "Adam"
speakerName2 = "Jerry"
speakerChoice2 = "Domi"
genPodcast = createPodcast(podcastScript, speakerName1, speakerChoice1, speakerName2, speakerChoice2)When creating the podcast script, we designated ‘Tom’ as the main host and ‘Jerry’ as the cohost. During the voice generation process, we’ll be using the ‘Adam’ voice for ‘Tom’ and the ‘Domi’ voice for ‘Jerry’.
We can use the below method to save our podcast script.
with open("/content/sample_data/genPodcast.mpeg", "wb") as f:
for pod in genPodcast:
f.write(pod)Finally, our podcast audio file is generated and saved as ‘genPodcast.mpeg’.
8. Generate Podcast Intro Music
To give our podcast a professional touch, we can incorporate an introductory music segment. To generate this introduction music, we’ll utilize the MusicGen model, available on HuggingFace.
MusicGen is a text-to-music model with the ability to create high-quality music samples based on text descriptions or audio prompts.
Here’s a sample prompt that we can use to generate the introduction music. Don’t hesitate to experiment with different prompts.
Create a musical composition that evokes a sense of tranquility and relaxation. Incorporate gentle melodies, soft harmonies, and gradual transitions to craft a soothing and smoothening music piece.Once the audio is generated, download it and import it to the colab notebook.
9. Bring the Podcast Together
At this point, we possess both the podcast audio file and the introduction music file. The next step involves merging these two files to create the complete, final podcast.
To combine these audio files we will use pydub package. It is versatile and allows us to load audio from various formats — MP3 and WAV files in our case and combine them in ways that we like.
We can use the below command to install this dependency.
!pip install pydubWith the dependency now installed, let’s proceed to merge the audio files using the pydub library. You can utilize the following code to combine the audio files and create the final podcast.
from pydub import AudioSegment
# Import your respective saved Audio files
music_intro = AudioSegment.from_file("/content/sample_data/intro_music.mp4","mp4")
podcast_content = AudioSegment.from_file("/content/sample_data/genPodcast.mpeg")
final_version = music_intro.append(podcast_content, crossfade=1500)
#Save your final audio file
final_version.export("/content/finalPodcast.mp3", format="mp3")Our podcast is now ready. An optional step we can take is to add an image to our final podcast audio script.
Here is our podcast episode which we generated using Gen AI.
If you’d like to access the complete notebook, please refer to the repository provided below.
